




Notebooks

Categories



Cells
Premium

BioTuring
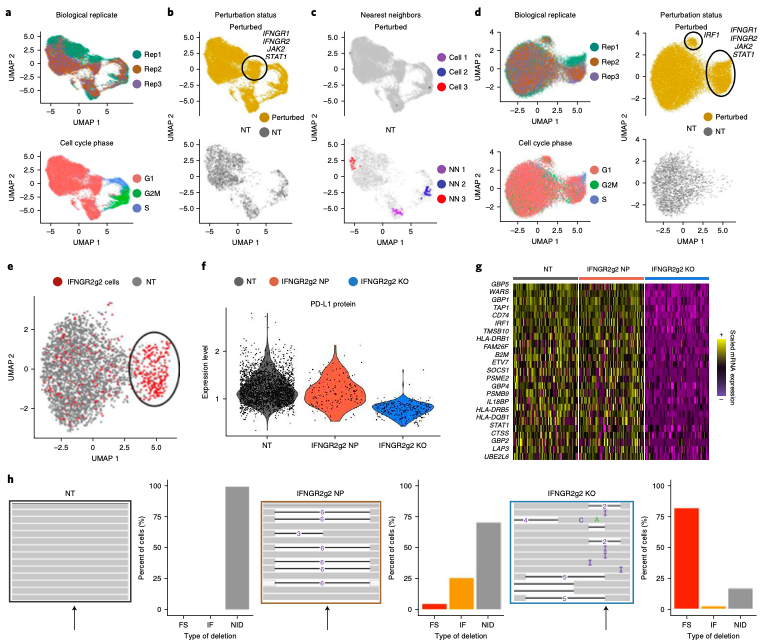
Expanded CRISPR-compatible CITE-seq (ECCITE-seq) which is built upon pooled CRISPR screens, allows to simultaneously measure transcriptomes, surface protein levels, and single-guide RNA (sgRNA) sequences at single-cell resolution. The technique enables multimodal characterization of each perturbation and effect exploration. However, it also encounters heterogeneity and complexity which can cause substantial noise into downstream analyses.
Mixscape (Papalexi, Efthymia, et al., 2021) is a computational framework proposed to substantially improve the signal-to-noise ratio in single-cell perturbation screens by identifying and removing confounding sources of variation.
In this notebooks, we demonstrate Mixscape's features using pertpy - a Python package offering a range of tools for perturbation analysis. The original pipeline of Mixscape implemented in R can be found here.

BioTuring
The development of large-scale single-cell atlases has allowed describing cell states in a more detailed manner. Meanwhile, current deep leanring methods enable rapid analysis of newly generated query datasets by mapping them into reference atlases.
expiMap (‘explainable programmable mapper’) Lotfollahi, Mohammad, et al. is one of the methods proposed for single-cell reference mapping. Furthermore, it incorporates prior knowledge from gene sets databases or users to analyze query data in the context of known gene programs (GPs).

BioTuring
In this notebook, we present COMMOT (COMMunication analysis by Optimal Transport) to infer cell-cell communication (CCC) in spatial transcriptomic, a package that infers CCC by simultaneously considering numerous ligand–receptor pairs for either spatial transcriptomic data or spatially annotated scRNA-seq data equipped with spatial distances between cells estimated from paired spatial imaging data.
A collective optimal transport method is developed to handle complex molecular interactions and spatial constraints. Furthermore, we introduce downstream analysis tools to infer spatial signaling directionality and genes regulated by signaling using machine learning models.
BioTuring
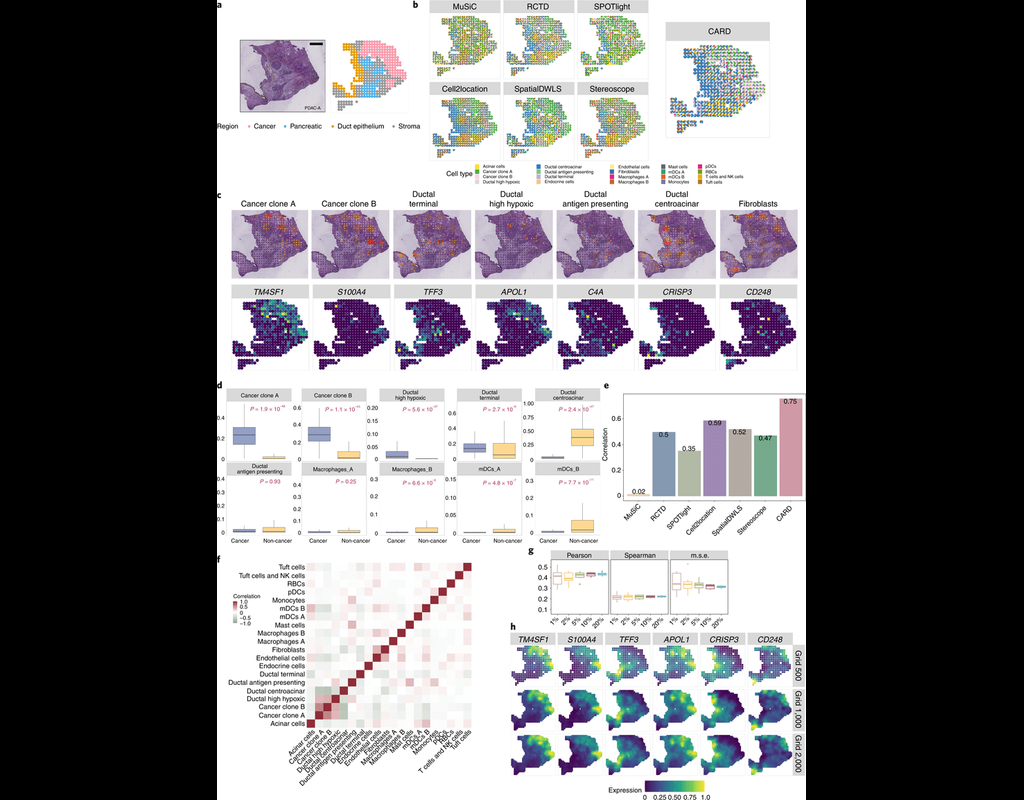
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.
Trends
BioTuring
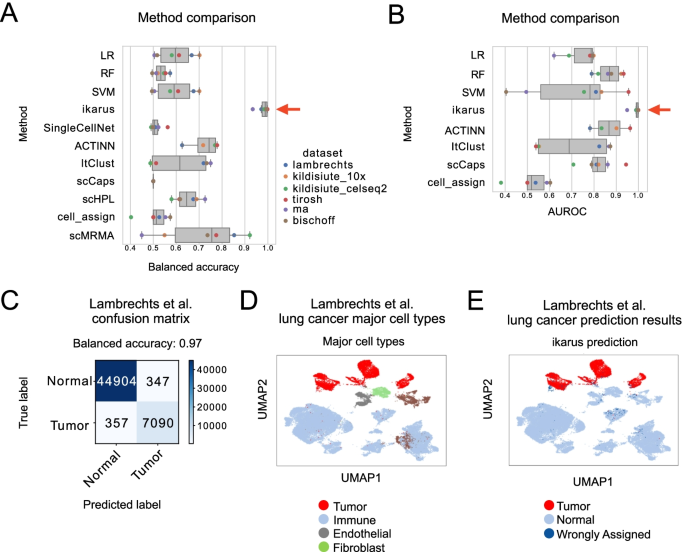
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.
BioTuring
This tool provides a user-friendly and automated way to analyze large-scale single-cell RNA-seq datasets stored in RDS (Seurat) format. It allows users to run various analysis tools on their data in one command, streamlining the analysis workflow and saving time.
Note that this notebook is only for the demonstration of the tool. User can run the tool directly through the command line.
Currently, we support:
- InferCNV - Identifying tumor cells at the single-cell level using machine learning