




Notebooks

Categories



Cells
Premium

BioTuring
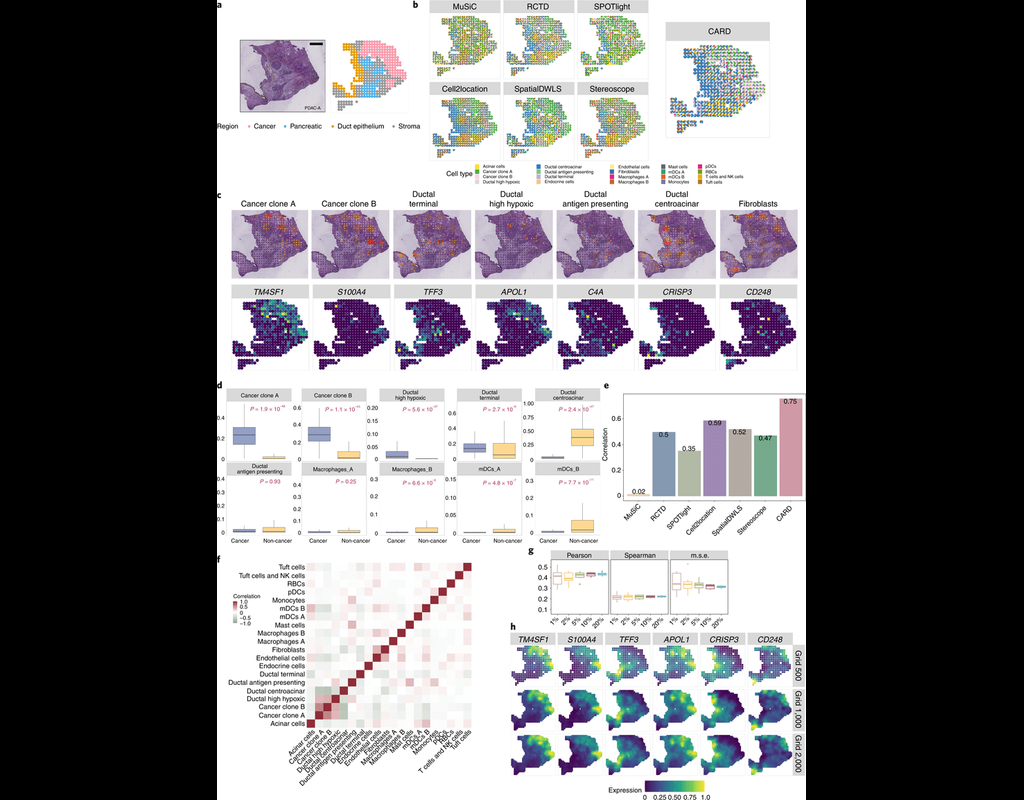
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.

BioTuring
In this notebook, we present COMMOT (COMMunication analysis by Optimal Transport) to infer cell-cell communication (CCC) in spatial transcriptomic, a package that infers CCC by simultaneously considering numerous ligand–receptor pairs for either spatial transcriptomic data or spatially annotated scRNA-seq data equipped with spatial distances between cells estimated from paired spatial imaging data.
A collective optimal transport method is developed to handle complex molecular interactions and spatial constraints. Furthermore, we introduce downstream analysis tools to infer spatial signaling directionality and genes regulated by signaling using machine learning models.

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolution.
Here, Runmin Wei (Siyuan He, Shanshan Bai, Emi Sei, Min Hu, Alastair Thompson, Ken Chen, Savitri Krishnamurthy & Nicholas E. Navin) developed a computational method called CellTrek that combines these two datasets to achieve single-cell spatial mapping through coembedding and metric learning approaches. They benchmarked CellTrek using simulation and in situ hybridization datasets, which demonstrated its accuracy and robustness.
They then applied CellTrek to existing mouse brain and kidney datasets and showed that CellTrek can detect topological patterns of different cell types and cell states. They performed single-cell RNA sequencing and spatial transcriptomics experiments on two ductal carcinoma in situ tissues and applied CellTrek to identify tumor subclones that were restricted to different ducts, and specific T-cell states adjacent to the tumor areas.
BioTuring
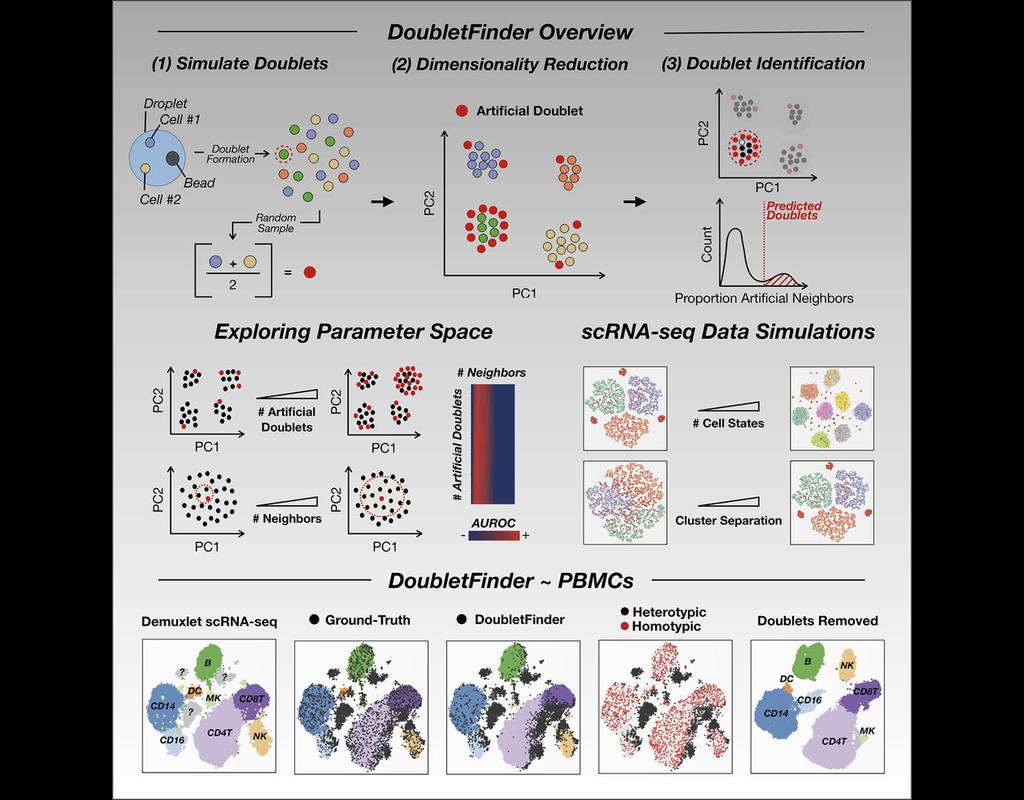
Single-cell RNA sequencing (scRNA-seq) data often encountered technical artifacts called "doublets" which are two cells that are sequenced under the same cellular barcode.
Doublets formed from different cell types or states are called heterotypic and homotypic otherwise. These factors constrain cell throughput and may result in misleading biological interpretations.
DoubletFinder (McGinnis, Murrow, and Gartner 2019) is one of the methods proposed for doublet detection. In this notebook, we will illustrate an example workflow of DoubletFinder. We use a 10x Genomics dataset which captures peripheral blood mononuclear cells (PBMCs) from a healthy donor stained with a panel of 31 TotalSeq™-B antibodies (BioLegend).
Trends
BioTuring
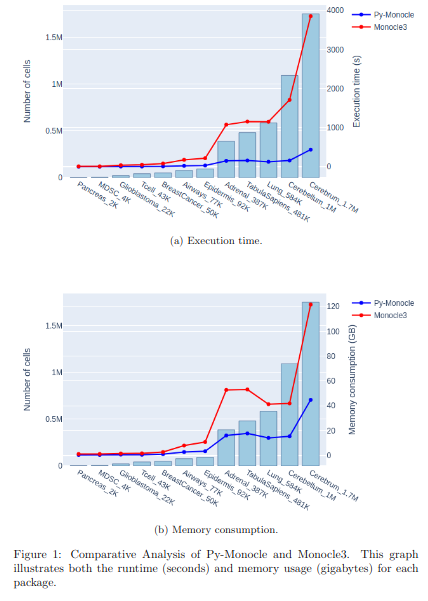
BioTuring Py-Monocle is a package tailored for computing pseudotime on large single-cell datasets. Implemented in Python and drawing inspiration from the Monocle3 package in R, our approach optimizes select steps for enhanced performance efficiency. Leveraging established Python libraries such as Numpy, and Scipy, this algorithm offers an economical solution for analyzing single-cell datasets.