




Notebooks

Categories



Cells
Premium


BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.

BioTuring
CellRank2 (Weiler et al, 2023) is a powerful framework for studying cellular fate using single-cell RNA sequencing data. It can handle millions of cells and different data types efficiently. This tool can identify cell fate and probabilities across various data sets. It also allows for analyzing transitions over time and uncovering key genes in developmental processes. Additionally, CellRank2 estimates cell-specific transcription and degradation rates, aiding in understanding differentiation trajectories and regulatory mechanisms.
In this notebook, we will use a primary tumor sample of patient T71 from the dataset GSE137804 (Dong R. et al, 2020) as an example. We have performed RNA-velocity analysis and pseudotime calculation on this dataset in scVelo (Bergen et al, 2020) notebook. The output will be then loaded into this CellRank2 notebook for further analysis.
This notebook is based on the tutorial provided on CellRank2 documentation. We have modified the notebook and changed the input data to show how the tool works on BioTuring's platform.
BioTuring
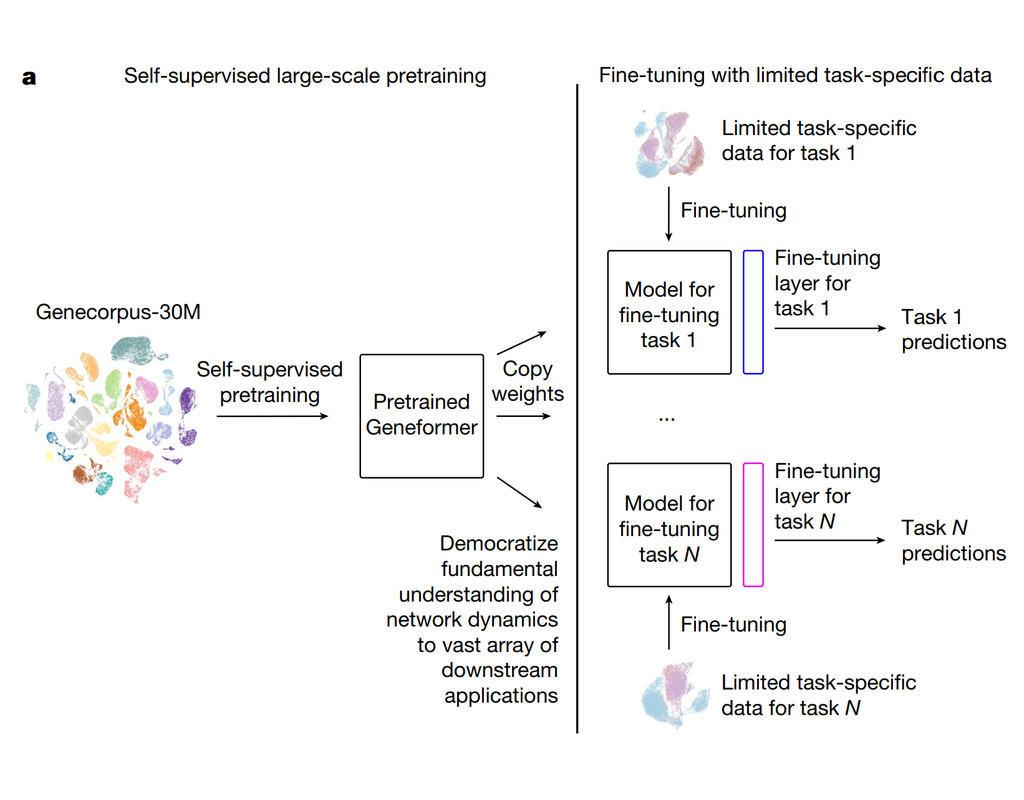
Geneformer is a foundation transformer model pretrained on a large-scale corpus of ~30 million single cell transcriptomes to enable context-aware predictions in settings with limited data in network biology. Here, we will demonstrate a basic workflow to work with ***Geneformer*** models.
These notebooks include the instruction to:
1. Prepare input datasets
2. Finetune Geneformer model to perform specific task
3. Using finetuning models for cell classification and gene classification application
BioTuring
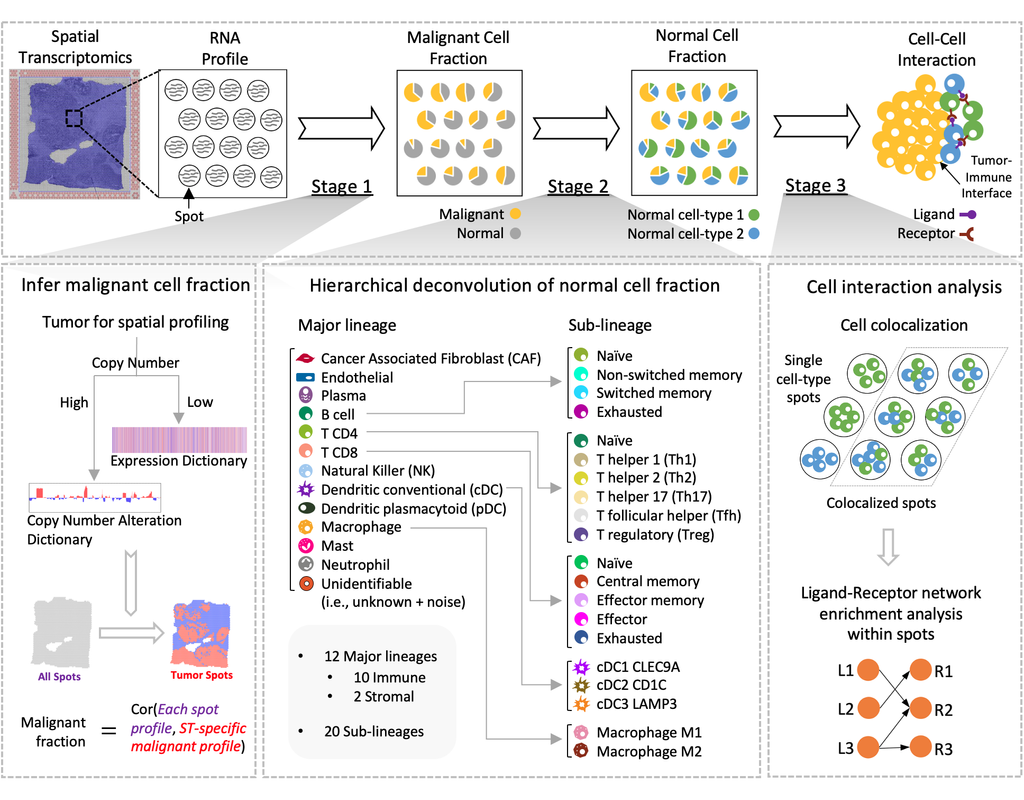
Spatial transcriptomics (ST) technology has allowed to capture of topographical gene expression profiling of tumor tissues, but single-cell resolution is potentially lost. Identifying cell identities in ST datasets from tumors or other samples remains challenging for existing cell-type deconvolution methods.
Spatial Cellular Estimator for Tumors (SpaCET) is an R package for analyzing cancer ST datasets to estimate cell lineages and intercellular interactions in the tumor microenvironment. Generally, SpaCET infers the malignant cell fraction through a gene pattern dictionary, then calibrates local cell densities and determines immune and stromal cell lineage fractions using a constrained regression model. Finally, the method can reveal putative cell-cell interactions in the tumor microenvironment.
In this notebook, we will illustrate an example workflow for cell type deconvolution and interaction analysis on breast cancer ST data from 10X Visium. The notebook is inspired by SpaCET's vignettes and modified to demonstrate how the tool works on BioTuring's platform.
Trends
BioTuring
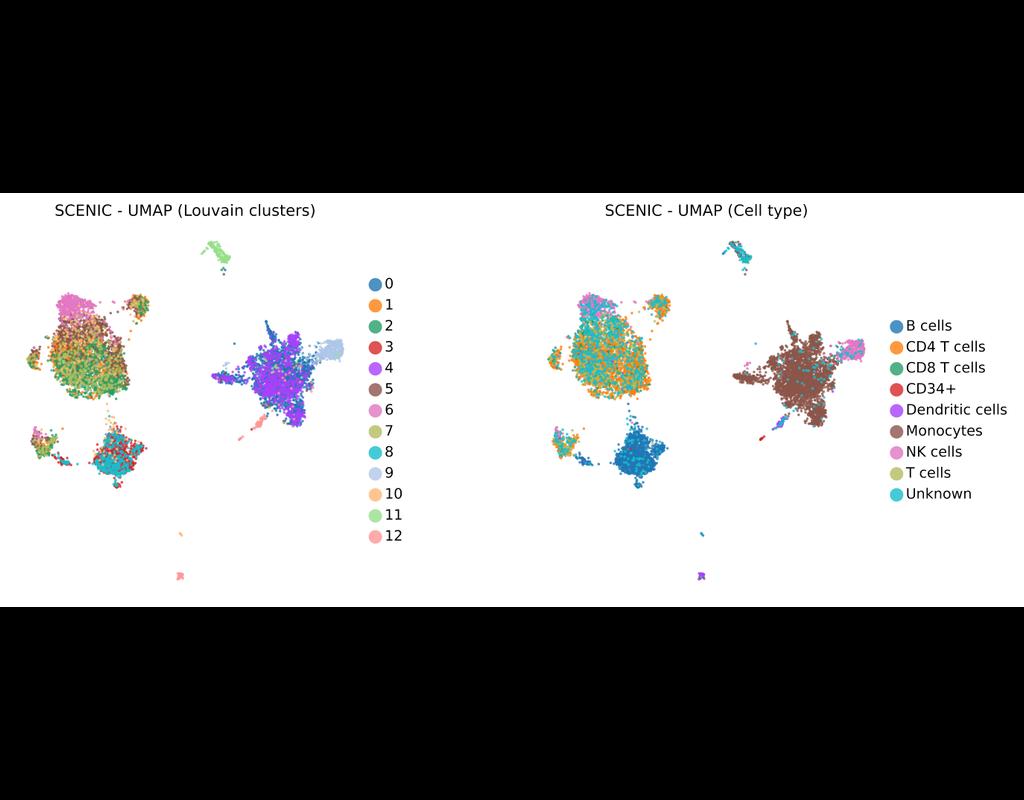
SCENIC Suite is a set of tools to study and decipher gene regulation. Its core is based on SCENIC (Single-Cell Regulatory Network Inference and Clustering) which enables you to infer transcription factors, gene regulatory networks and cell types from single-cell RNA-seq data.
pySCENIC is a lightning-fast python implementation of the SCENIC pipeline (Single-Cell Regulatory Network Inference and Clustering) which enables biologists to infer transcription factors, gene regulatory networks and cell types from single-cell RNA-seq data.