




Notebooks

Categories



Cells
Premium

BioTuring
Power analyses are considered important factors in designing high-quality experiments. However, such analyses remain a challenge in single-cell RNA-seq studies due to the presence of hierarchical structure within the data (Zimmerman et al., 2021). As cells sampled from the same individual share genetic and environmental backgrounds, these cells are more correlated than cells sampled from different individuals. Currently, most power analyses and hypothesis tests (e.g., differential expression) in scRNA-seq data treat cells as if they were independent, thus ignoring the intra-sample correlation, which could lead to incorrect inferences.
Hierarchicell (Zimmerman, K.D. and Langefeld, C.D., 2021) is an R package proposed to estimate power for testing hypotheses of differential expression in scRNA-seq data while considering the hierarchical correlation structure that exists in the data. The method offers four important categories of functions: data loading and cleaning, empirical estimation of distributions, simulating expression data, and computing type 1 error or power.
In this notebook, we will illustrate an example workflow of Hierarchicell. The notebook is inspired by Hierarchicell's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
scVI-tools (single-cell variational inference tools) is a package for end-to-end analysis of single-cell omics data primarily developed and maintained by the Yosef Lab at UC Berkeley. scvi-tools has two components
- Interface for easy use of a range of probabilistic models for single-cell omics (e.g., scVI, scANVI, totalVI).
- Tools to build new probabilistic models, which are powered by PyTorch, PyTorch Lightning, and Pyro.
BioTuring
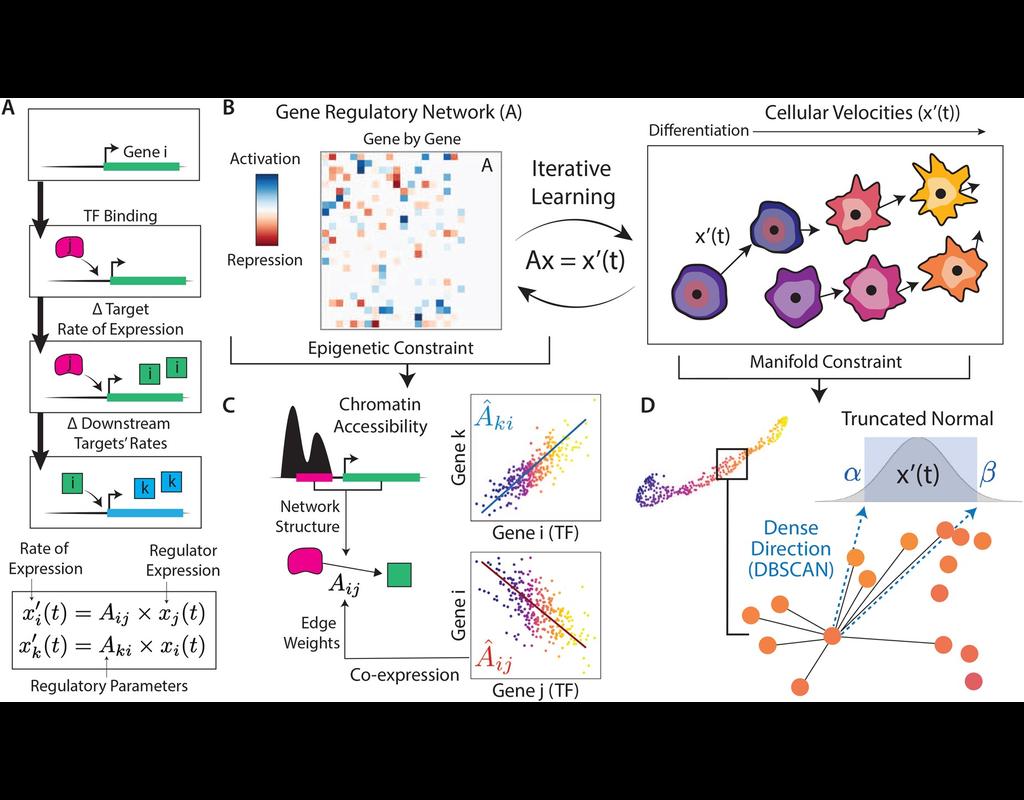
In the realm of transcriptional dynamics, understanding the intricate interplay of regulatory proteins is crucial for deciphering processes ranging from normal development to disease progression. However, traditional RNA velocity methods often overlook the underlying regulatory drivers of gene expression changes over time. This gap in knowledge hinders our ability to unravel the mechanistic intricacies of these dynamic processes.
scKINETICs (Key regulatory Interaction NETwork for Inferring Cell Speed) (Burdziak et al, 2023) offers a dynamic model for gene expression changes that simultaneously learns per-cell transcriptional velocities and a governing gene regulatory network. By employing an expectation-maximization approach, scKINETICS quantifies the impact of each regulatory element on its target genes, incorporating insights from epigenetic data, gene-gene coexpression patterns and constraints dictated by the phenotypic manifold.
BioTuring
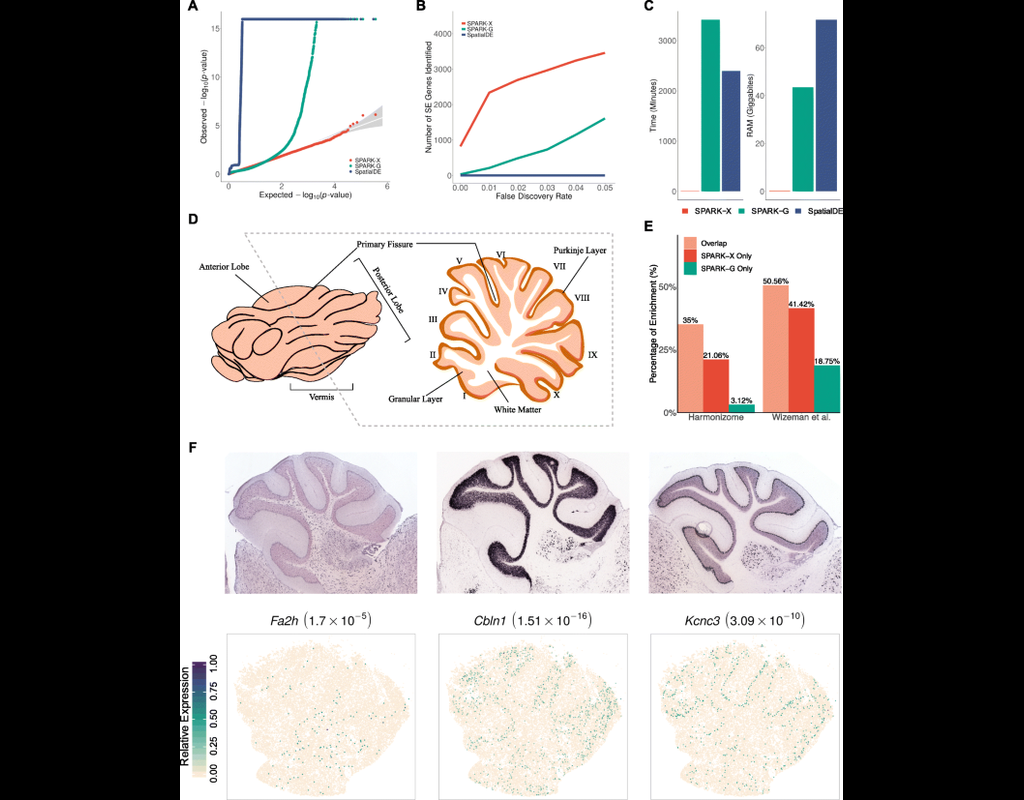
Spatial transcriptomic studies are becoming increasingly common and large, posing important statistical and computational challenges for many analytic tasks. Here, we present SPARK-X, a non-parametric method for rapid and effective detection of spatially expressed genes in large spatial transcriptomic studies.
SPARK-X not only produces effective type I error control and high power but also brings orders of magnitude computational savings. We apply SPARK-X to analyze three large datasets, one of which is only analyzable by SPARK-X. In these data, SPARK-X identifies many spatially expressed genes including those that are spatially expressed within the same cell type, revealing new biological insights.
Trends
BioTuring
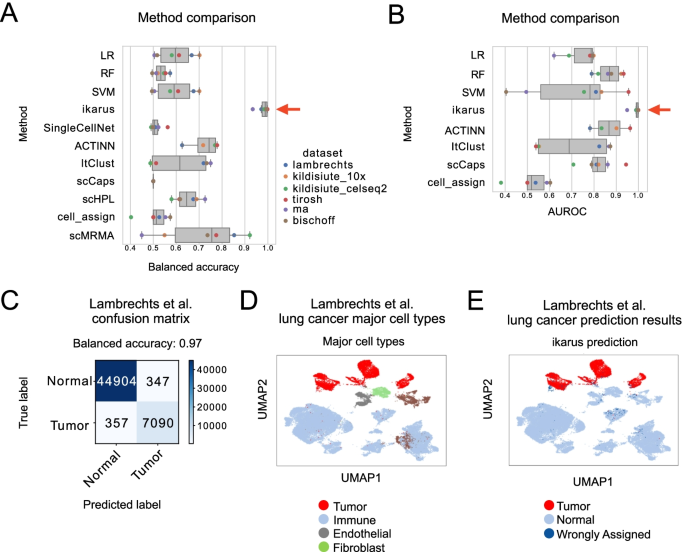
Tumors are complex tissues of cancerous cells surrounded by a heterogeneous cellular microenvironment with which they interact. Single-cell sequencing enables molecular characterization of single cells within the tumor. However, cell annotation—the assignment of cell type or cell state to each sequenced cell—is a challenge, especially identifying tumor cells within single-cell or spatial sequencing experiments.
Here, we propose ikarus, a machine learning pipeline aimed at distinguishing tumor cells from normal cells at the single-cell level. We test ikarus on multiple single-cell datasets, showing that it achieves high sensitivity and specificity in multiple experimental contexts.
**InferCNV** is a Bayesian method, which agglomerates the expression signal of genomically adjointed genes to ascertain whether there is a gain or loss of a certain larger genomic segment. We have used **inferCNV** to call copy number variations in all samples used in the manuscript.
BioTuring
This tool provides a user-friendly and automated way to analyze large-scale single-cell RNA-seq datasets stored in RDS (Seurat) format. It allows users to run various analysis tools on their data in one command, streamlining the analysis workflow and saving time.
Note that this notebook is only for the demonstration of the tool. User can run the tool directly through the command line.
Currently, we support:
- InferCNV - Identifying tumor cells at the single-cell level using machine learning