




Notebooks

Categories



Cells
Premium

BioTuring
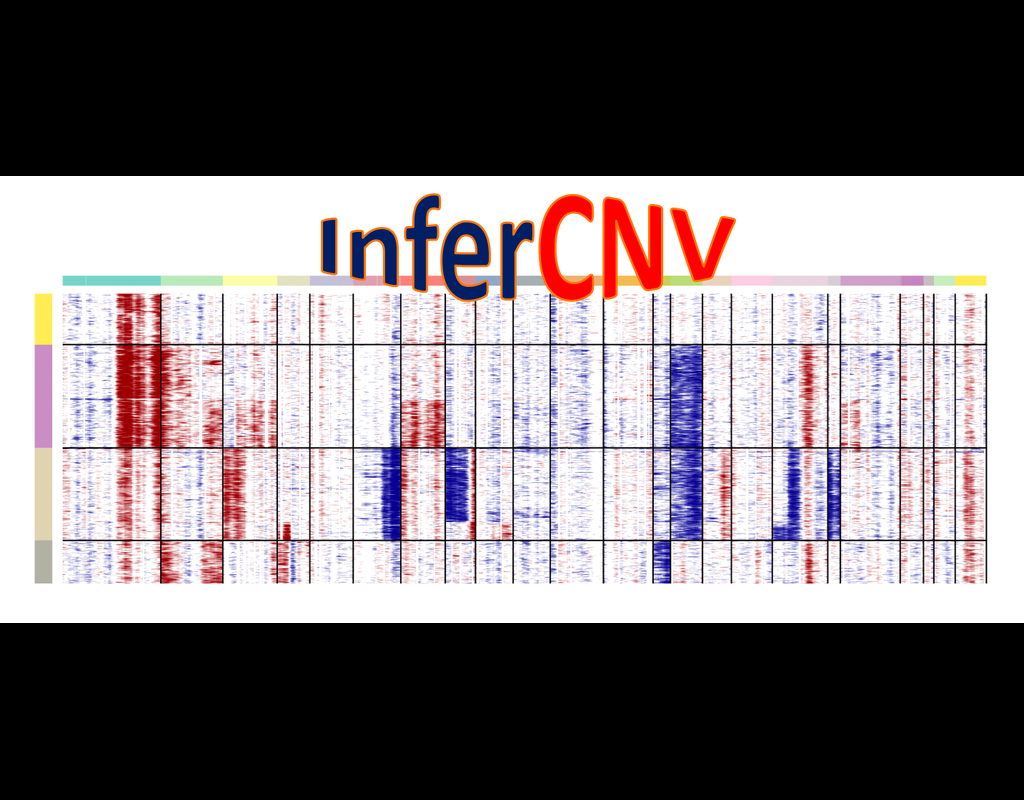
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
BioTuring
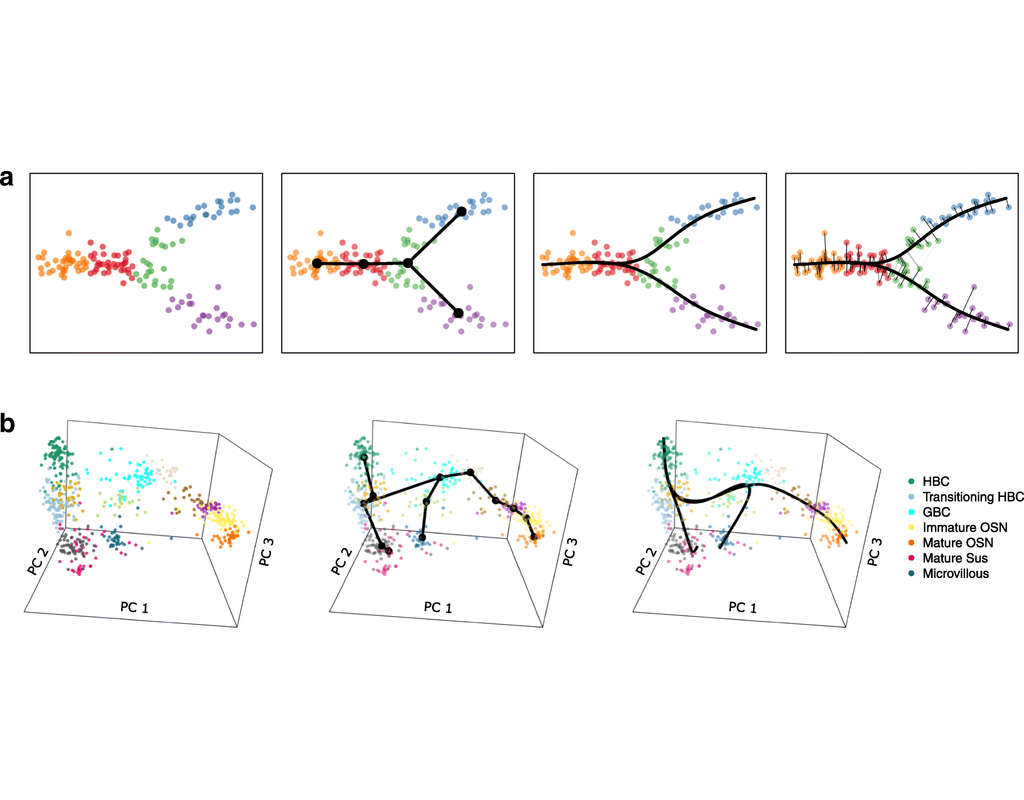
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolution.
Here, Runmin Wei (Siyuan He, Shanshan Bai, Emi Sei, Min Hu, Alastair Thompson, Ken Chen, Savitri Krishnamurthy & Nicholas E. Navin) developed a computational method called CellTrek that combines these two datasets to achieve single-cell spatial mapping through coembedding and metric learning approaches. They benchmarked CellTrek using simulation and in situ hybridization datasets, which demonstrated its accuracy and robustness.
They then applied CellTrek to existing mouse brain and kidney datasets and showed that CellTrek can detect topological patterns of different cell types and cell states. They performed single-cell RNA sequencing and spatial transcriptomics experiments on two ductal carcinoma in situ tissues and applied CellTrek to identify tumor subclones that were restricted to different ducts, and specific T-cell states adjacent to the tumor areas.
BioTuring
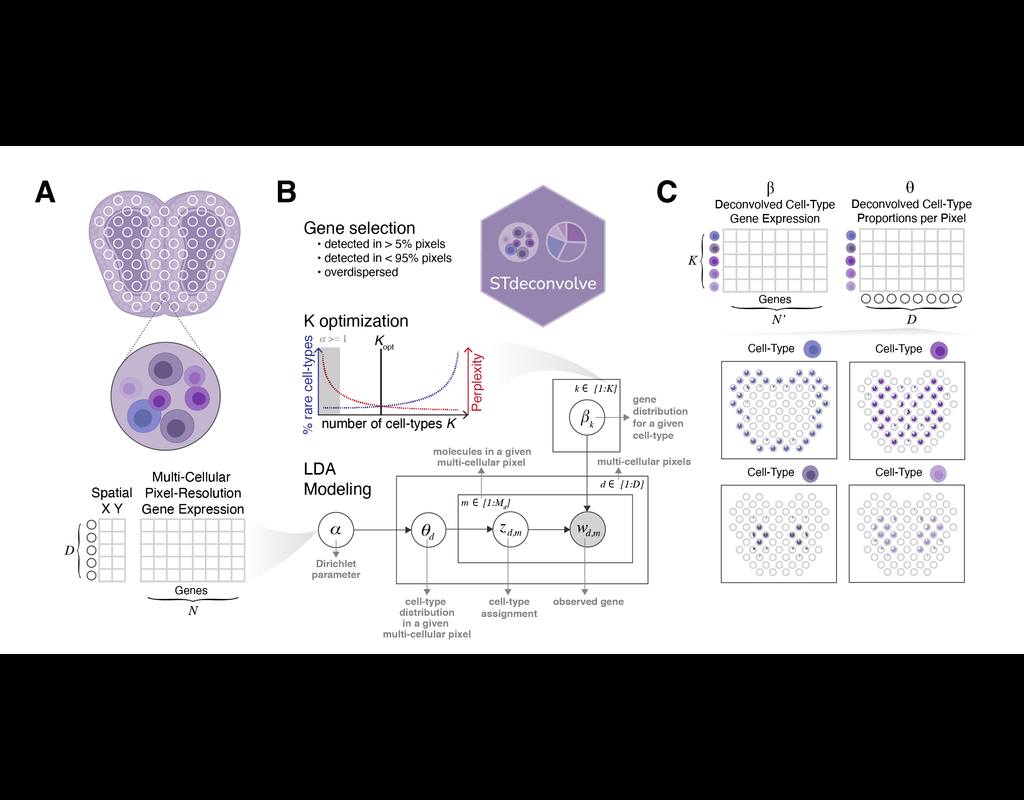
Recent technological advancements have enabled spatially resolved transcriptomic profiling but at multi-cellular pixel resolution, thereby hindering the identification of cell-type-specific spatial patterns and gene expression variation.
To address this challenge, we develop STdeconvolve as a reference-free approach to deconvolve underlying cell types comprising such multi-cellular pixel resolution spatial transcriptomics (ST) datasets. Using simulated as well as real ST datasets from diverse spatial transcriptomics technologies comprising a variety of spatial resolutions such as Spatial Transcriptomics, 10X Visium, DBiT-seq, and Slide-seq, we show that STdeconvolve can effectively recover cell-type transcriptional profiles and their proportional representation within pixels without reliance on external single-cell transcriptomics references.
**STdeconvolve** provides comparable performance to existing reference-based methods when suitable single-cell references are available, as well as potentially superior performance when suitable single-cell references are not available.
STdeconvolve is available as an open-source R software package with the source code available at https://github.com/JEFworks-Lab/STdeconvolve .
Trends

BioTuring
Single-cell RNA-seq datasets in diverse biological and clinical conditions provide great opportunities for the full transcriptional characterization of cell types.
However, the integration of these datasets is challeging as they remain biological and techinical differences. **Harmony** is an algorithm allowing fast, sensitive and accurate single-cell data integration.