




Notebooks

Categories



Cells
Premium

BioTuring
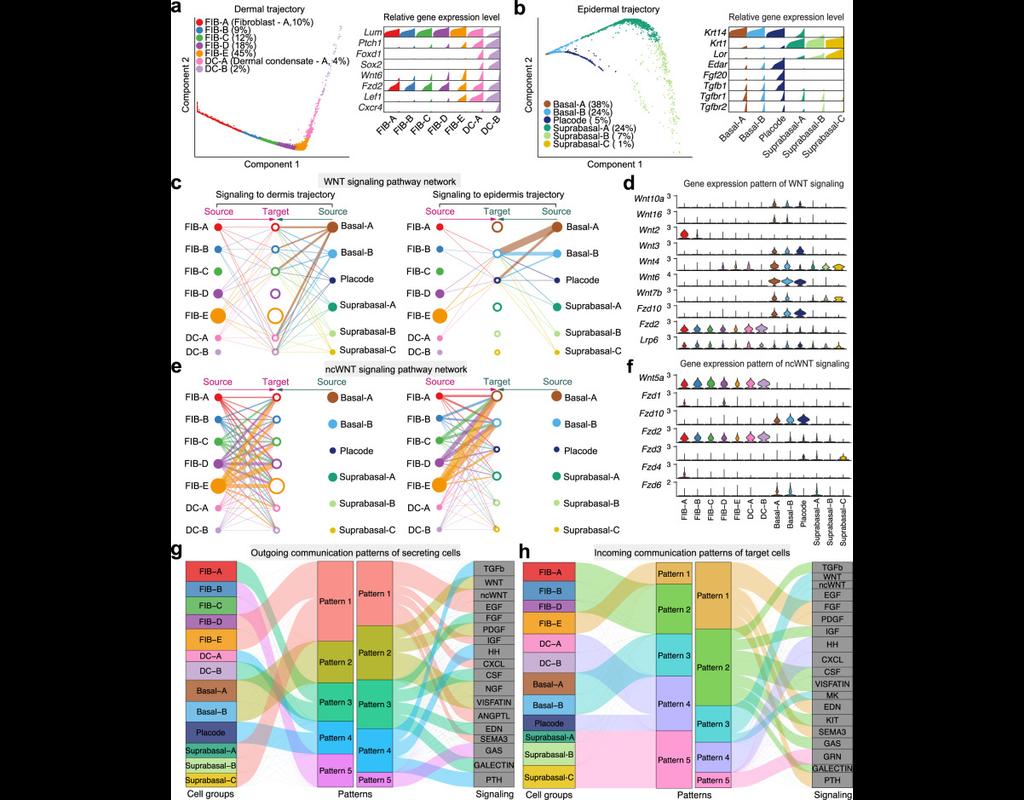
Understanding global communications among cells requires accurate representation of cell-cell signaling links and effective systems-level analyses of those links.
We construct a database of interactions among ligands, receptors and their cofactors that accurately represent known heteromeric molecular complexes. We then develop **CellChat**, a tool that is able to quantitatively infer and analyze intercellular communication networks from single-cell RNA-sequencing (scRNA-seq) data.
CellChat predicts major signaling inputs and outputs for cells and how those cells and signals coordinate for functions using network analysis and pattern recognition approaches. Through manifold learning and quantitative contrasts, CellChat classifies signaling pathways and delineates conserved and context-specific pathways across different datasets.
Applying **CellChat** to mouse and human skin datasets shows its ability to extract complex signaling patterns.
BioTuring
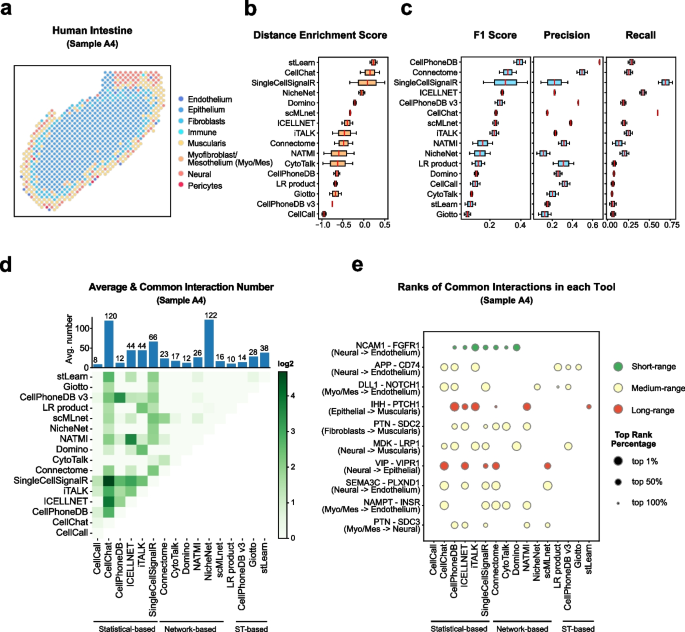
Cell–cell communication mediated by ligand–receptor complexes is critical to coordinating diverse biological processes, such as development, differentiation and inflammation.
To investigate how the context-dependent crosstalk of different cell types enables physiological processes to proceed, we developed CellPhoneDB, a novel repository of ligands, receptors and their interactions. In contrast to other repositories, our database takes into account the subunit architecture of both ligands and receptors, representing heteromeric complexes accurately.
We integrated our resource with a statistical framework that predicts enriched cellular interactions between two cell types from single-cell transcriptomics data. Here, we outline the structure and content of our repository, provide procedures for inferring cell–cell communication networks from single-cell RNA sequencing data and present a practical step-by-step guide to help implement the protocol.
CellPhoneDB v.2.0 is an updated version of our resource that incorporates additional functionalities to enable users to introduce new interacting molecules and reduces the time and resources needed to interrogate large datasets.
CellPhoneDB v.2.0 is publicly available, both as code and as a user-friendly web interface; it can be used by both experts and researchers with little experience in computational genomics.
In our protocol, we demonstrate how to evaluate meaningful biological interactions with CellPhoneDB v.2.0 using published datasets. This protocol typically takes ~2 h to complete, from installation to statistical analysis and visualization, for a dataset of ~10 GB, 10,000 cells and 19 cell types, and using five threads.
BioTuring
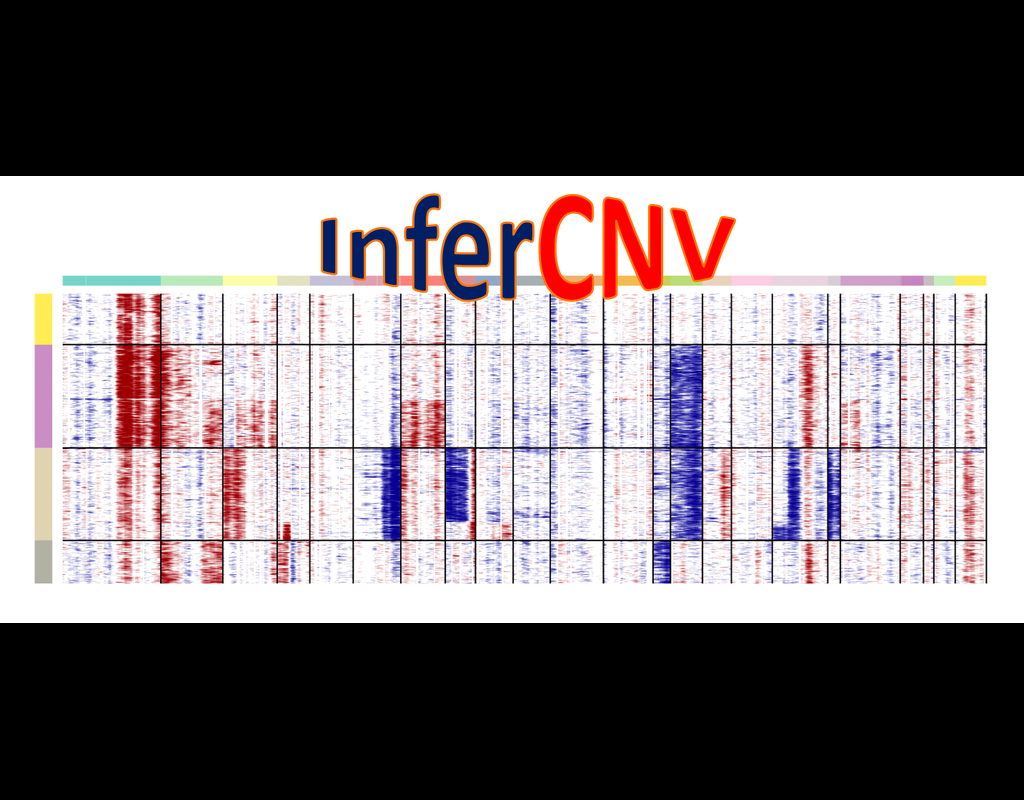
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
BioTuring
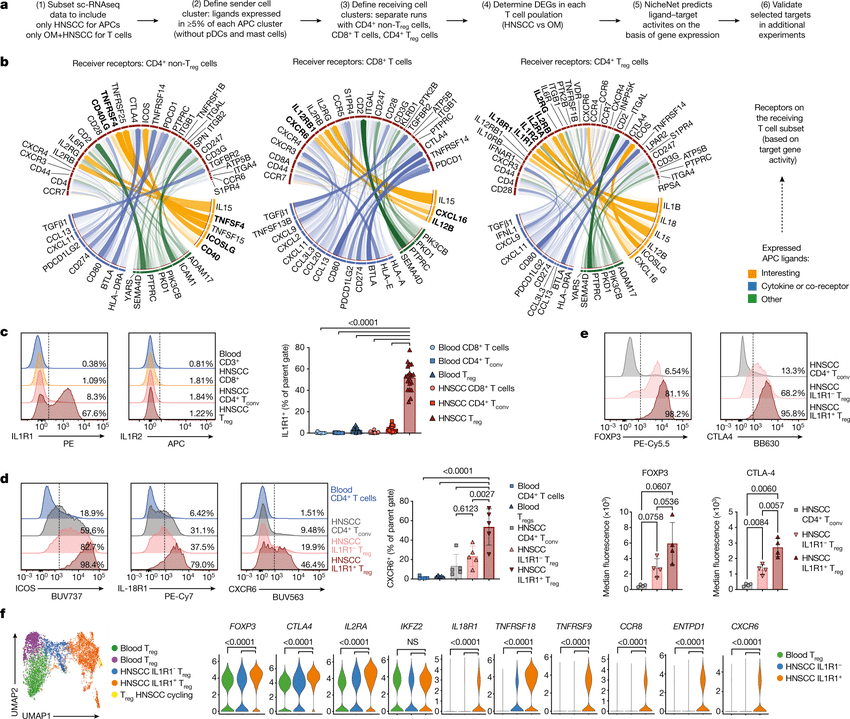
Computational methods that model how the gene expression of a cell is influenced by interacting cells are lacking.
We present NicheNet, a method that predicts ligand–target links between interacting cells by combining their expression data with prior knowledge of signaling and gene regulatory networks.
We applied NicheNet to the tumor and immune cell microenvironment data and demonstrated that NicheNet can infer active ligands and their gene regulatory effects on interacting cells.
Trends
BioTuring
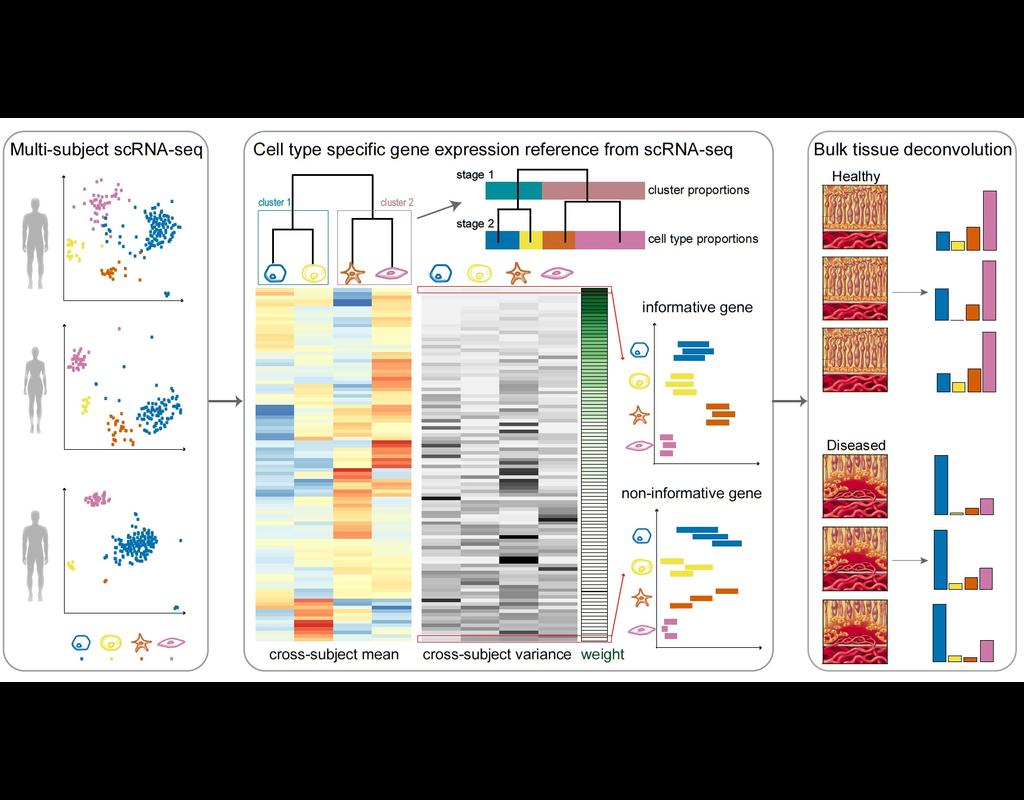
Knowledge of cell type composition in disease relevant tissues is an important step towards the identification of cellular targets of disease. MuSiC is a method that utilizes cell-type specific gene expression from single-cell RNA sequencing (RNA-seq) data to characterize cell type compositions from bulk RNA-seq data in complex tissues.
By appropriate weighting of genes showing cross-subject and cross-cell consistency, MuSiC enables the transfer of cell type-specific gene expression information from one dataset to another.
MuSiC enables the characterization of cellular heterogeneity of complex tissues for understanding of disease mechanisms. As bulk tissue data are more easily accessible than single-cell RNA-seq, MuSiC allows the utilization of the vast amounts of disease relevant bulk tissue RNA-seq data for elucidating cell type contributions in disease.
This notebook provides a walk through tutorial on how to use MuSiC to estimate cell type proportions from bulk sequencing data based on multi-subject single cell data by reproducing the analysis in MuSiC paper, now is published on Nature Communications.