




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
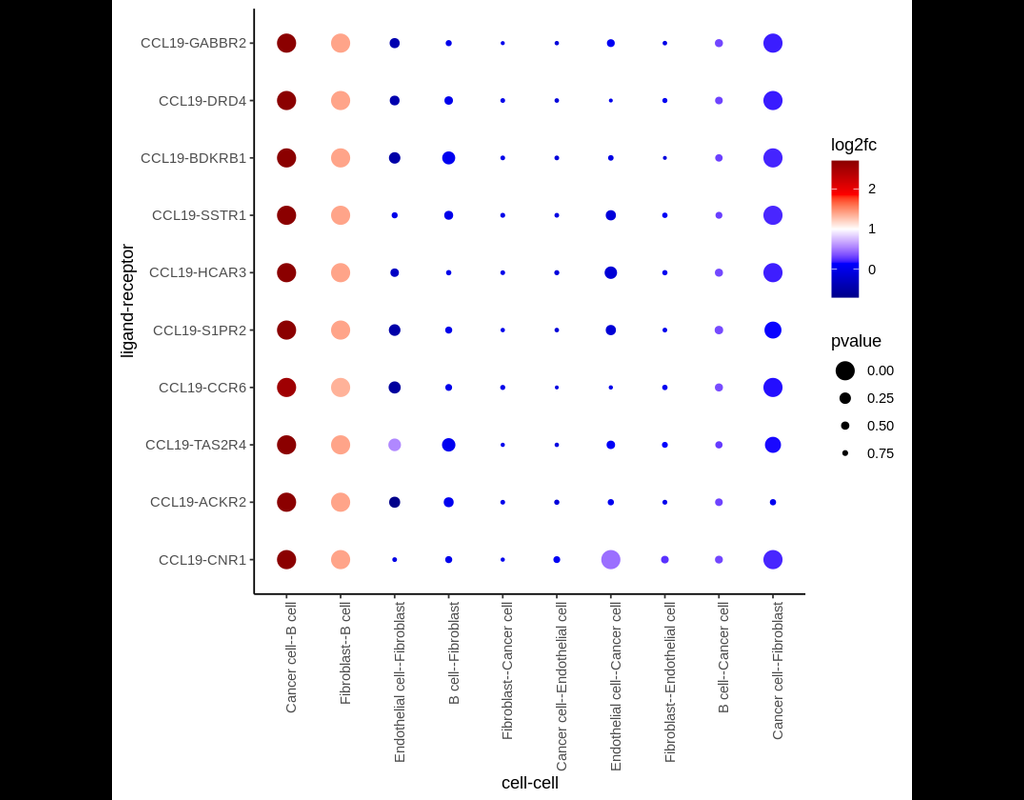
Single-cell RNA data allows cell-cell communications (***CCC***) methods to infer CCC at either the individual cell or cell cluster/cell type level, but physical distances between cells are not preserved Almet, Axel A., et al., (2021). On the other hand, spatial data provides spatial distances between cells, but single-cell or gene resolution is potentially lost. Therefore, integrating two types of data in a proper manner can complement their strengths and limitations, from that improve CCC analysis.
In this pipeline, we analyze CCC on Visium data with single-cell data as a reference. The pipeline includes 4 sub-notebooks as following
01-deconvolution: This step involves deconvolution and cell type annotation for Visium data, with cell type information obtained from a relevant single-cell dataset. The deconvolution method is SpatialDWLS which is integrated in Giotto package.
02-giotto: performs spatial based CCC and expression based CCC on Visium data using Giotto method.
03-nichenet: performs spatial based CCC and expression based CCC on Visium data using NicheNet method.
04-visualization: visualizes CCC results obtained from Giotto and NicheNet.
BioTuring
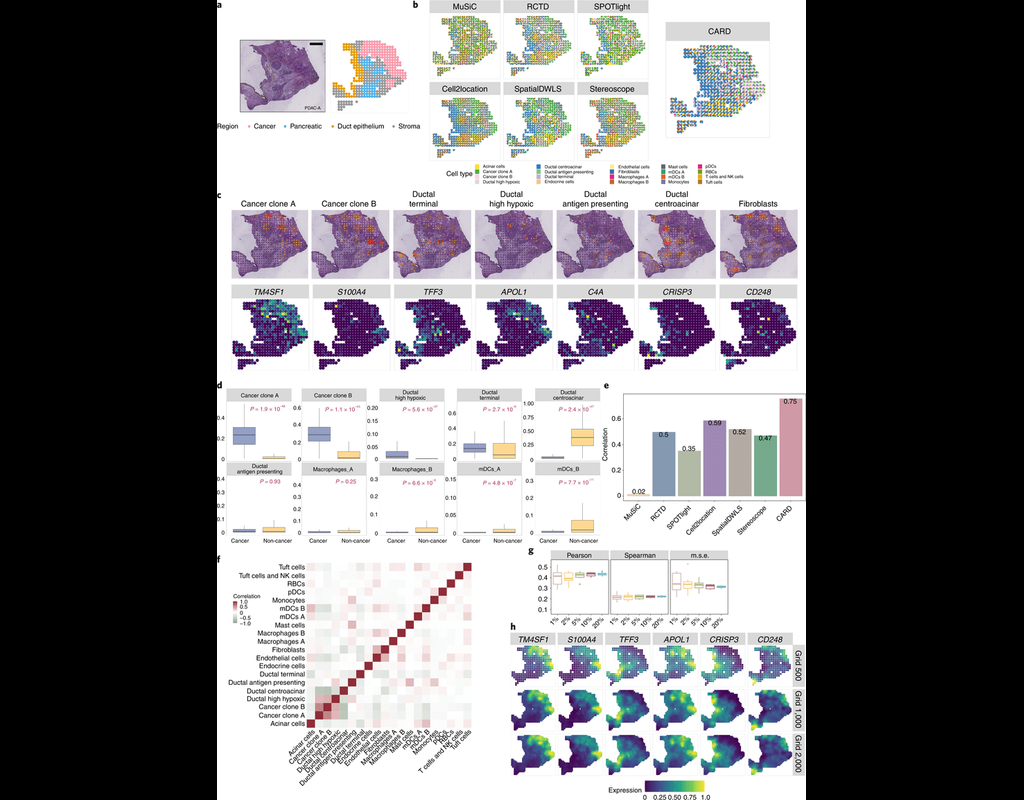
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.
BioTuring
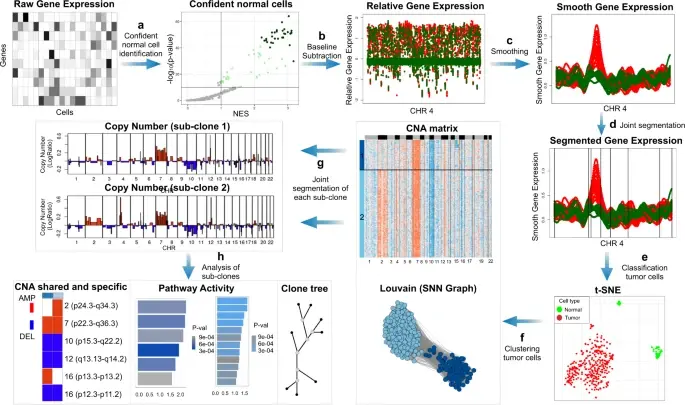
In the realm of cancer research, grasping the intricacies of intratumor heterogeneity and its interplay with the immune system is paramount for deciphering treatment resistance and tumor progression. While single-cell RNA sequencing unveils diverse transcriptional programs, the challenge persists in automatically discerning malignant cells from non-malignant ones within complex datasets featuring varying coverage depths. Thus, there arises a compelling need for an automated solution to this classification conundrum.
SCEVAN (De Falco et al., 2023), a variational algorithm, is designed to autonomously identify the clonal copy number substructure of tumors using single-cell data. It automatically separates malignant cells from non-malignant ones, and subsequently, groups of malignant cells are examined through an optimization-driven joint segmentation process.
BioTuring
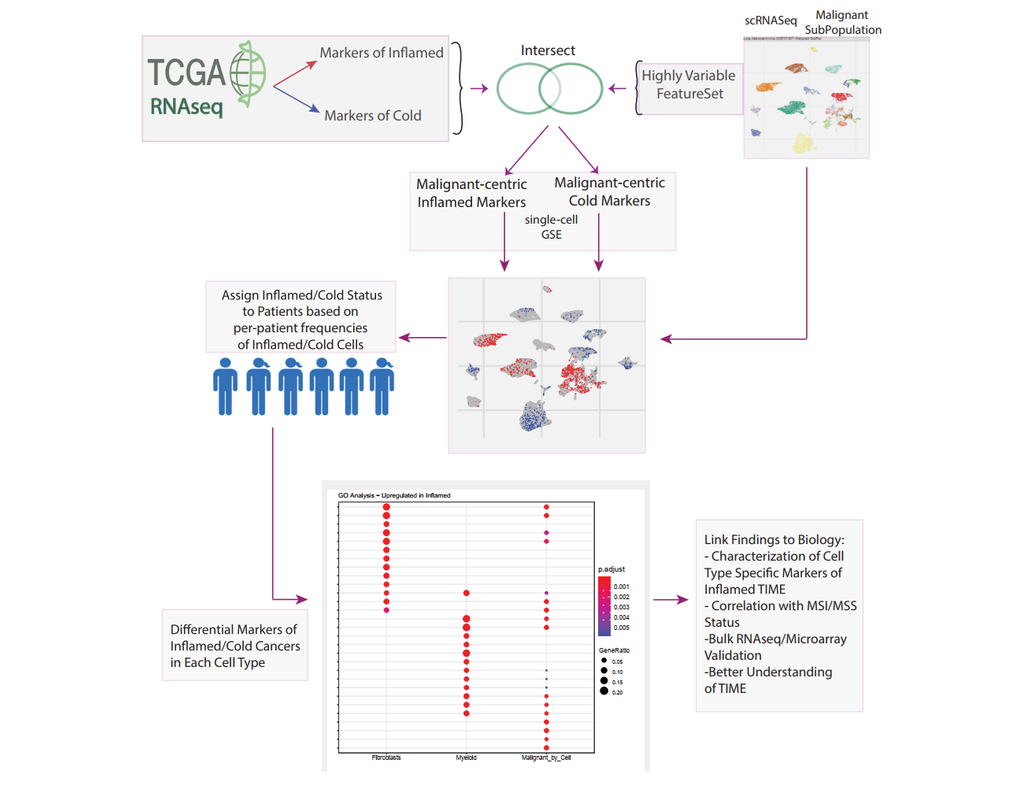
The development of immune checkpoint-based immunotherapies has been a major advancement in the treatment of cancer, with a subset of patients exhibiting durable clinical responses. A predictive biomarker for immunotherapy response is the pre-existing T-cell infiltration in the tumor immune microenvironment (TIME).
Bulk transcriptomics-based approaches can quantify the degree of T-cell infiltration using deconvolution methods and identify additional markers of inflamed/cold cancers at the bulk level. However, bulk techniques are unable to identify biomarkers of individual cell types. Although single-cell RNA sequencing (scRNAseq) assays are now being used to profile the TIME, to our knowledge there is no method of identifying patients with a T-cell inflamed TIME from scRNAseq data. Here, we describe a method, iBRIDGE, which integrates reference bulk RNAseq data with the malignant subset of scRNAseq datasets to identify patients with a T-cell inflamed TIME.
Utilizing two datasets with matched bulk data, we show iBRIDGE results correlated highly with bulk assessments (0.85 and 0.9 correlation coefficients). Using iBRIDGE, we identified markers of inflamed phenotypes in malignant cells, myeloid cells, and fibroblasts, establishing type I and type II interferon pathways as dominant signals, especially in malignant and myeloid cells, and finding the TGFβ-driven mesenchymal phenotype not only in fibroblasts but also in malignant cells.
Besides relative classification, per-patient average iBRIDGE scores and independent RNAScope quantifications were utilized for threshold-based absolute classification. Moreover, iBRIDGE can be applied to in vitro grown cancer cell lines and can identify the cell lines that are adapted from inflamed/cold patient tumors.