




Notebooks

Categories



Cells
Notebook
Premium

BioTuring
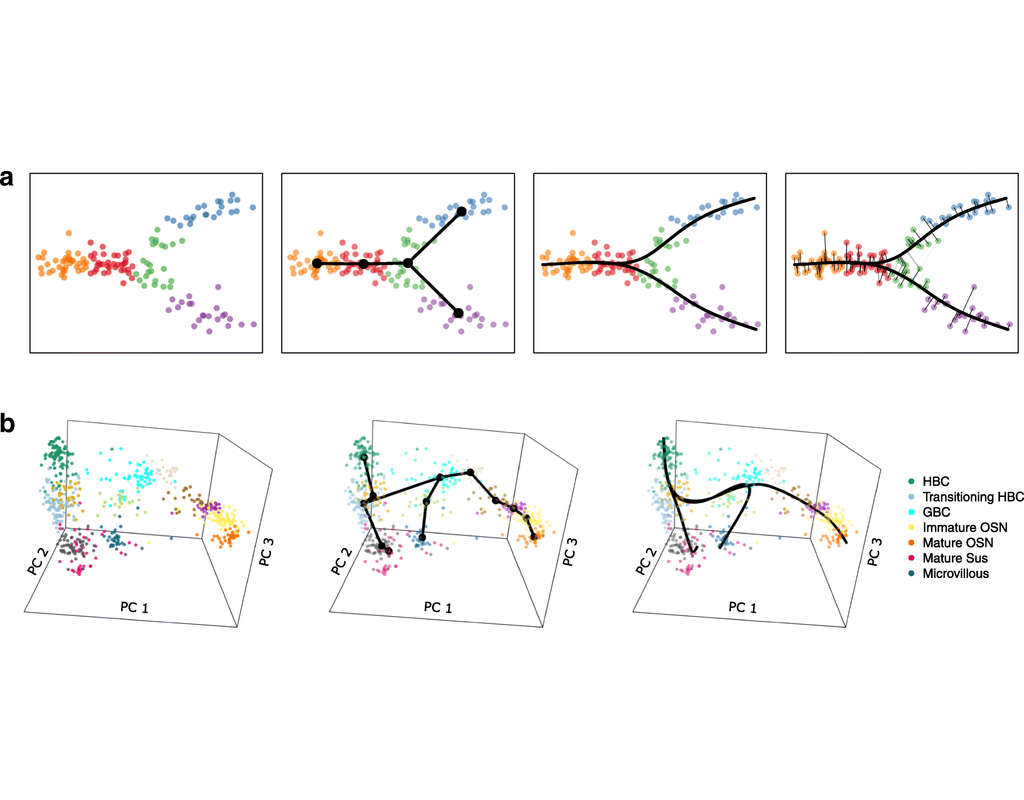
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.

BioTuring
Advances in multi-omics have led to an explosion of multimodal datasets to address questions from basic biology to translation. While these data provide novel opportunities for discovery, they also pose management and analysis challenges, thus motivating the development of tailored computational solutions. `muon` is a Python framework for multimodal omics.
It introduces multimodal data containers as `MuData` object. The package also provides state of the art methods for multi-omics data integration. `muon` allows the analysis of both unimodal omics and multimodal omics.
BioTuring
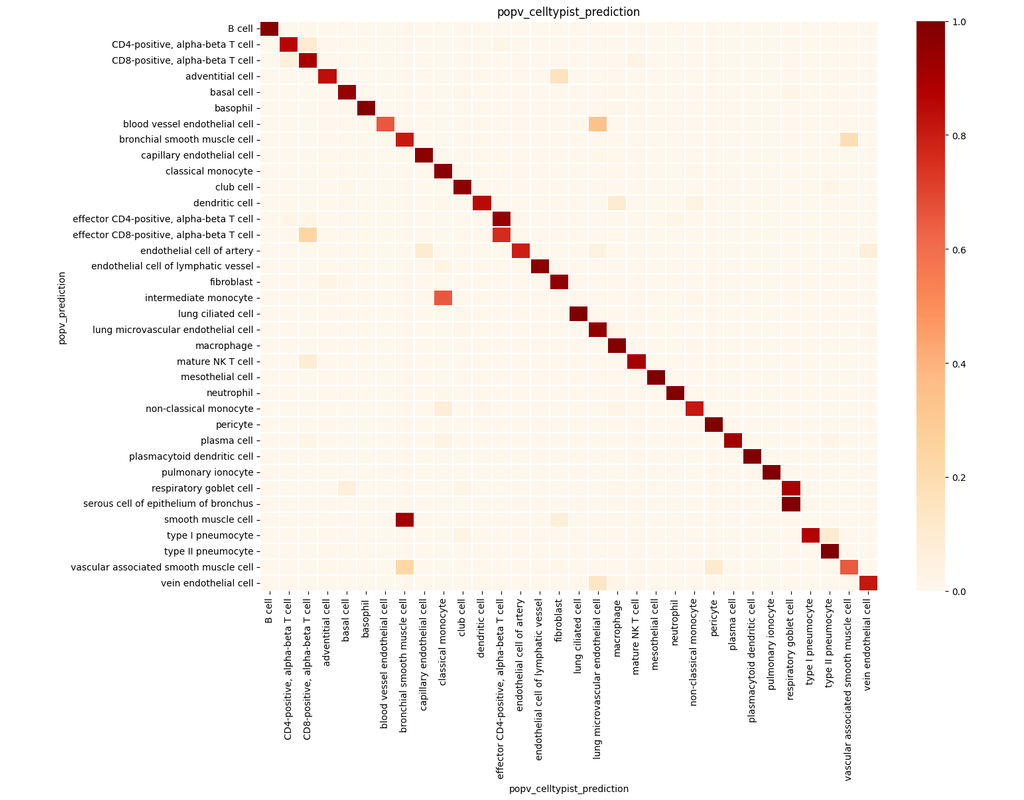
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.

BioTuring
Single-cell RNA sequencing methods can profile the transcriptomes of single cells but cannot preserve spatial information. Conversely, spatial transcriptomics assays can profile spatial regions in tissue sections but do not have single-cell resolution.
Here, Runmin Wei (Siyuan He, Shanshan Bai, Emi Sei, Min Hu, Alastair Thompson, Ken Chen, Savitri Krishnamurthy & Nicholas E. Navin) developed a computational method called CellTrek that combines these two datasets to achieve single-cell spatial mapping through coembedding and metric learning approaches. They benchmarked CellTrek using simulation and in situ hybridization datasets, which demonstrated its accuracy and robustness.
They then applied CellTrek to existing mouse brain and kidney datasets and showed that CellTrek can detect topological patterns of different cell types and cell states. They performed single-cell RNA sequencing and spatial transcriptomics experiments on two ductal carcinoma in situ tissues and applied CellTrek to identify tumor subclones that were restricted to different ducts, and specific T-cell states adjacent to the tumor areas.