




Notebooks

Categories



Cells
Premium

BioTuring
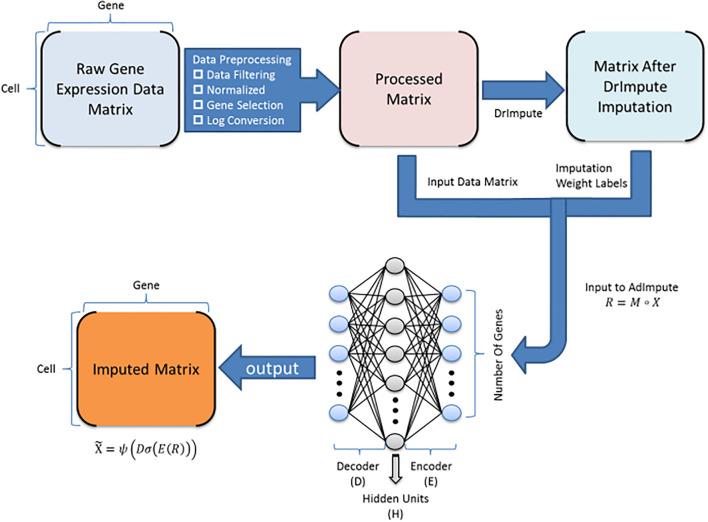
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
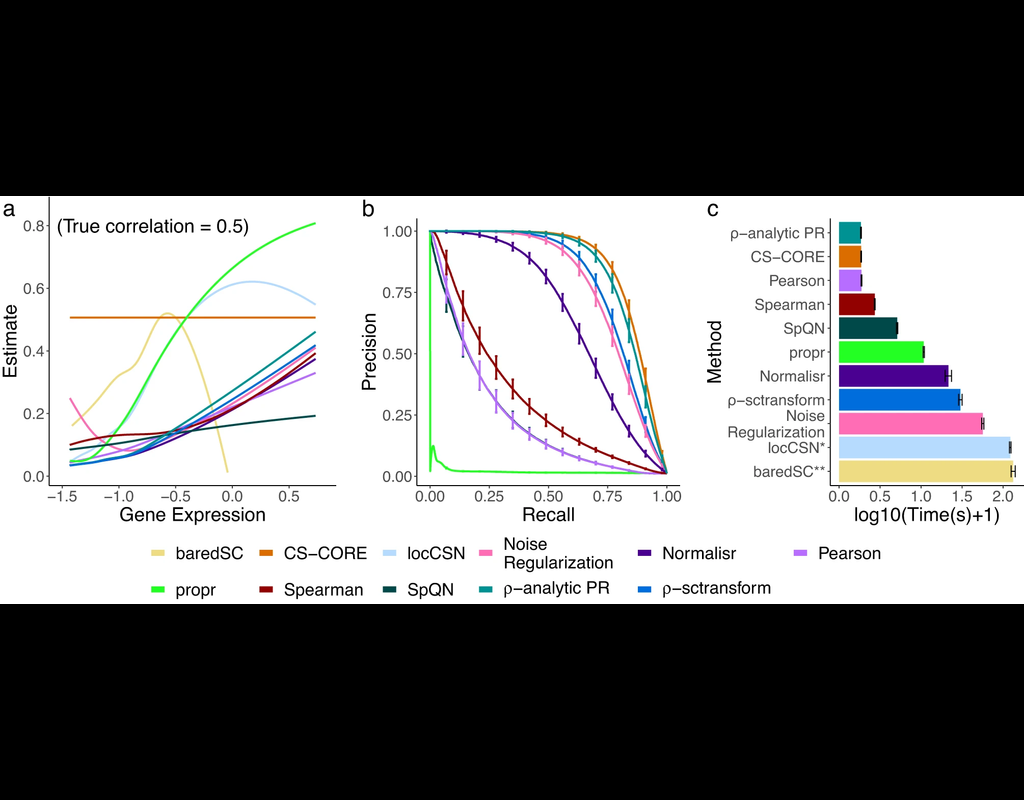
The recent development of single-cell RNA-sequencing (scRNA-seq) technology has enabled us to infer cell-type-specific co-expression networks, enhancing our understanding of cell-type-specific biological functions. However, existing methods proposed for this task still face challenges due to unique characteristics in scRNA-seq data, such as high sequencing depth variations across cells and measurement errors.
CS-CORE (Su, C., Xu, Z., Shan, X. et al., 2023), an R package for cell-type-specific co-expression inference, explicitly models sequencing depth variations and measurement errors in scRNA-seq data.
In this notebook, we will illustrate an example workflow of CS-CORE using a dataset of Peripheral Blood Mononuclear Cells (PBMC) from COVID patients and healthy controls (Wilk et al., 2020). The notebook content is inspired by CS-CORE's vignette and modified to demonstrate how the tool works on BioTuring's platform.
BioTuring
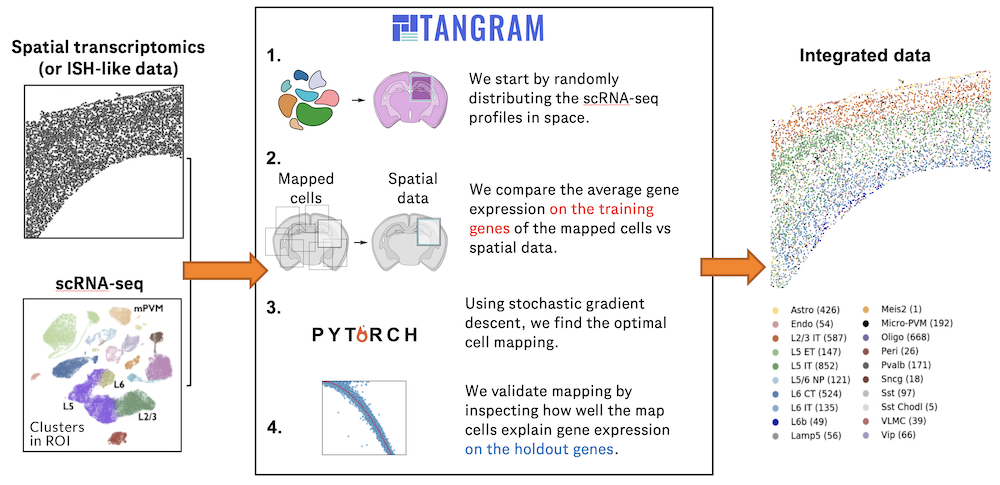
Charting an organs’ biological atlas requires us to spatially resolve the entire single-cell transcriptome, and to relate such cellular features to the anatomical scale. Single-cell and single-nucleus RNA-seq (sc/snRNA-seq) can profile cells comprehensively, but lose spatial information.
Spatial transcriptomics allows for spatial measurements, but at lower resolution and with limited sensitivity. Targeted in situ technologies solve both issues, but are limited in gene throughput. To overcome these limitations we present Tangram, a method that aligns sc/snRNA-seq data to various forms of spatial data collected from the same region, including MERFISH, STARmap, smFISH, Spatial Transcriptomics (Visium) and histological images.
**Tangram** can map any type of sc/snRNA-seq data, including multimodal data such as those from SHARE-seq, which we used to reveal spatial patterns of chromatin accessibility. We demonstrate Tangram on healthy mouse brain tissue, by reconstructing a genome-wide anatomically integrated spatial map at single-cell resolution of the visual and somatomotor areas.

BioTuring
Single-cell RNA-seq datasets in diverse biological and clinical conditions provide great opportunities for the full transcriptional characterization of cell types.
However, the integration of these datasets is challeging as they remain biological and techinical differences. **Harmony** is an algorithm allowing fast, sensitive and accurate single-cell data integration.
Trends
BioTuring
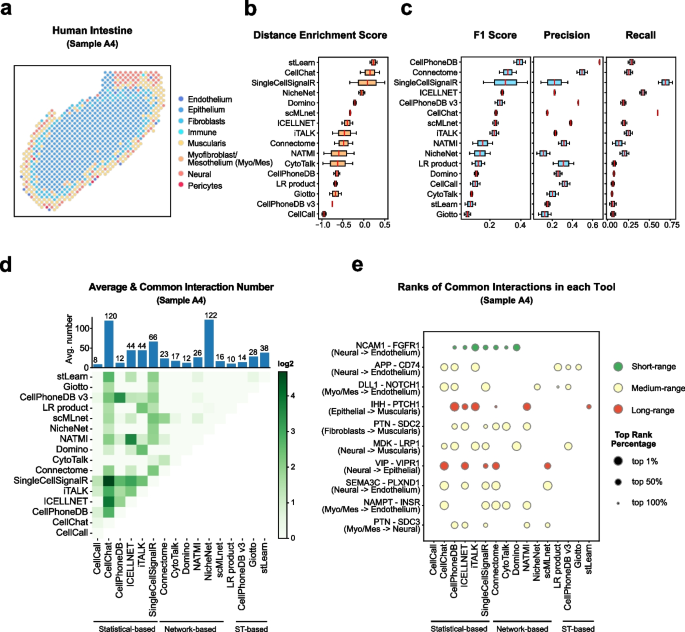
Cell–cell communication mediated by ligand–receptor complexes is critical to coordinating diverse biological processes, such as development, differentiation and inflammation.
To investigate how the context-dependent crosstalk of different cell types enables physiological processes to proceed, we developed CellPhoneDB, a novel repository of ligands, receptors and their interactions. In contrast to other repositories, our database takes into account the subunit architecture of both ligands and receptors, representing heteromeric complexes accurately.
We integrated our resource with a statistical framework that predicts enriched cellular interactions between two cell types from single-cell transcriptomics data. Here, we outline the structure and content of our repository, provide procedures for inferring cell–cell communication networks from single-cell RNA sequencing data and present a practical step-by-step guide to help implement the protocol.
CellPhoneDB v.2.0 is an updated version of our resource that incorporates additional functionalities to enable users to introduce new interacting molecules and reduces the time and resources needed to interrogate large datasets.
CellPhoneDB v.2.0 is publicly available, both as code and as a user-friendly web interface; it can be used by both experts and researchers with little experience in computational genomics.
In our protocol, we demonstrate how to evaluate meaningful biological interactions with CellPhoneDB v.2.0 using published datasets. This protocol typically takes ~2 h to complete, from installation to statistical analysis and visualization, for a dataset of ~10 GB, 10,000 cells and 19 cell types, and using five threads.